Machine learning applications, big data analytics, and data science deployment in the real world, only accounts for 25% of the total work involved. 50% is allocated to readying data for analytics and machine learning purposes, and the leftover 25% goes towards making the insights and conclusions drawn from models easily absorbed in a large scale. This is then all assembled by the data pipeline. The data pipeline is essentially the driving force behind machine learning. Without it, there can be no long-lasting success.
The following four principles are pivotal to understanding the data pipeline and alternative big data architecture:
Perspective
Pipeline
Possibilities
Production
Keep reading for an explanation on each of these principles.
Perspective

When building data analytics and machine learning applications, there are three very important roleplayers present, namely: data scientists, engineers, and business managers.
The data scientist will be the one concerned with finding the strongest and most cost-effective model to solve a given problem using the data at hand.
The engineer, on the other hand, will employ innovative strategies in either building something new and reliable, or discovering ways to improve on existing models.
Lastly, the business manager is responsible for using science and engineering in order to offer something of great value to customers.
Since this article will focus more on the engineering perspective, we’ve included a list of desired engineering characteristics pertaining to the data pipeline:
- Accessibility – data must be easily accessible to data scientists for hypothesis evaluation and model experimentation
- Scalability – the ability to scale as the data amount increases while keeping costs low
- Efficiency – data and machine learning being ready within a specified time
- Monitoring – automatic alerts about the health of the data and the pipeline
Pipeline

At face value, it’s impossible to know the true value of data. Only once data is turned into actionable insight and that insight is speedily delivered can its value truly be revealed.
Enter the data pipeline.
This is the master constructor, linking the entire operation together end-to-end. It begins with collecting data, changing the data into actionable insights, using the data to train a model which again delivers insights, and in turn, applying these insights to the model to ensure that the business goals are met in areas where action needs to be taken.
A data pipeline has 5 stages grouped into 3 heads:
- Data engineering: collection, ingestion, preparation (~50% effort)
- Analytics/Machine Learning: computation (~25% effort)
- Delivery: presentation (~25% effort)
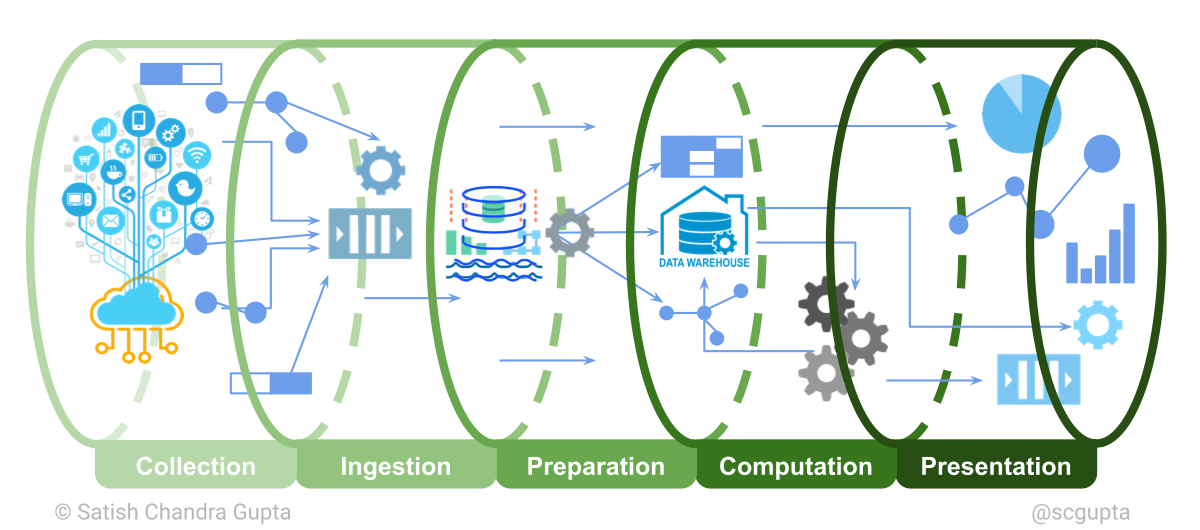
Data Lake vs. Data Warehouse
The data lake refers to all data in its natural form as it was received. Most of the time, this is in segments or files. The data warehouse refers to stored data that is cleaned and transformed together with catalog and schema. Data in both the data lake and the data warehouse can be of different types: structured, semi-structured, binary, and real-time event streams.
The lake and the warehouse can be physically housed in different locations, but that is optional. An interface can also be used through which the warehouse can be materialized over the lake. This is dependent on the speed requirements and cost constraints.
Exploratory Data Analysis
Exploratory Data Analysis is used to examine and visualise data sets and produce hypotheses. This process helps to identify variations in collected data, collect new data, and confirm hypotheses. This one of the best ways to improve data analytics.
If your Data Warehouse is well maintained with catalogs, schema, and accessibility through a query language, EDA is expedited.
Possibilities
In order to make the right choice when deciding upon the most appropriate architectural solution for data analytics, you need to ask yourself a couple of questions:
- Do you need real-time insights or model updates?
- What is the staleness tolerance of your application?
- What are the cost constraints?
Once you’ve answered these questions, the batch and streaming process of the Lambda Architecture needs to be taken into account.
Lambda Architecture is comprised of 3 different layers:
- Batch layer: offers high production rate, extensive, inexpensive map-reduce batch processing, but greater latency
- Speed layer: offers real-time stream processing, but at a greater cost and may exceed memory limit at high data volume
- Serving layer: When the output from batch processing is ready, it merges with the output of the stream processing to provide broad results in the form of pre-computed views or adhoc queries.
This image helps better explain the open source technology used in creating all the stages in the big data pipeline:
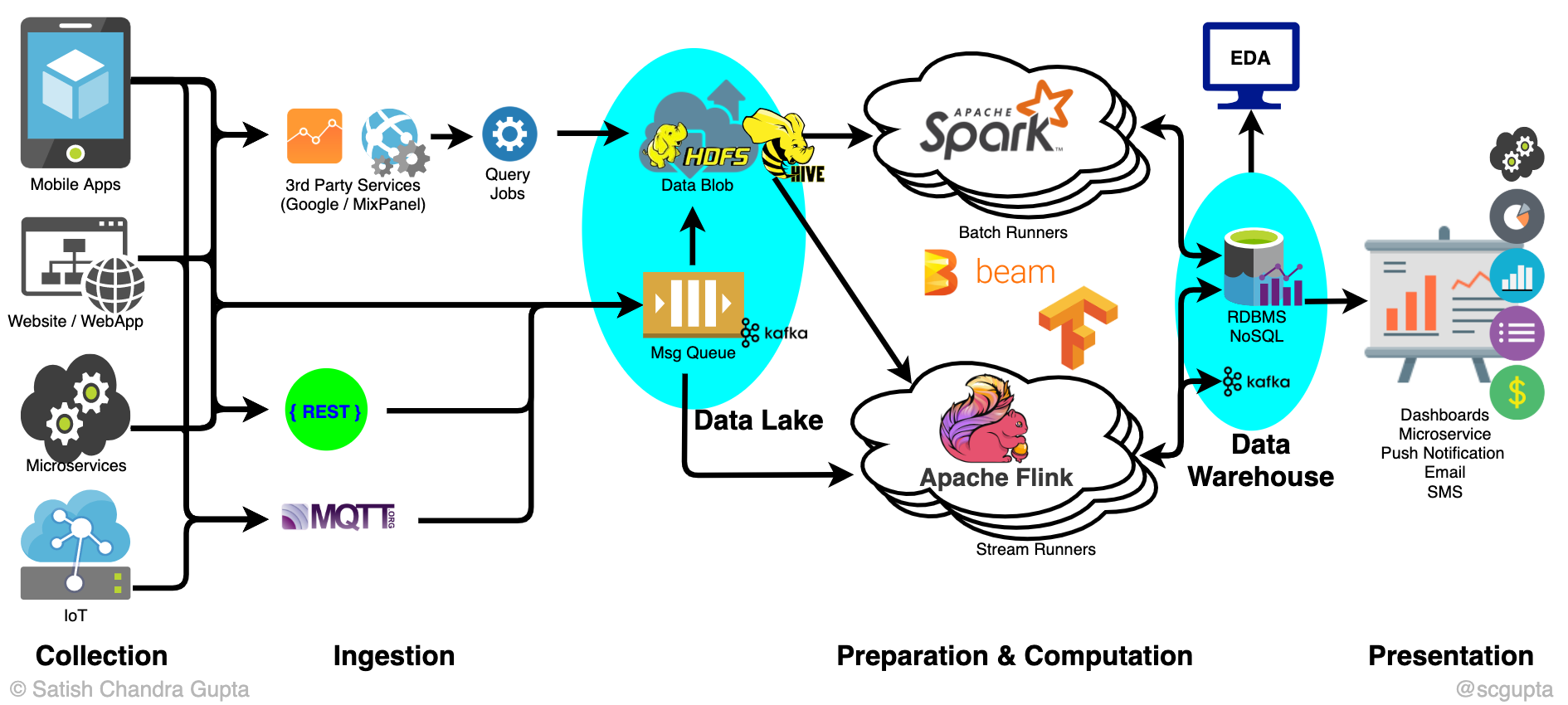
No matter which big data tech and architecture you decide upon, there are key elements that define them:
- HTTP/MQTT Endpoints for data consumption, as well as delivering of results. Many frameworks and technologies exist for this.
- Pub/Sub Message Queue for consumption of streaming data in high volumes. Kafka is the existing choice in this regard.
- Low-Cost High-Volume Data Store for both the data lake and the data warehouse, Hadoop HDFS, or cloud blob storage such as AWS S3.
- Query and Catalog Infrastructure for data lake transformation to a data warehouse. Apache Hive is the favoured choice here.
- Map-Reduce Batch Compute engine for high throughput processing. Use Hadoop Map-Reduce and Apache Spark.
- Stream Compute for latency-sensitive processing. Choices like Apache Storm, Apache Flink, and Apache Beam are perfectly suited here.
- Machine Learning Frameworks for data science and machine learning. Popular choices here are Scikit-Learn, TensorFlow, and PyTorch.
- Low-Latency Data Stores for result storage. SQL and NoSQL data stores are typically used in this case.
- Deployment orchestration alternatives are Hadoop YARN, Kubernetes/Kubeflow.
Scale and efficiency are dependent upon the following:
- Throughput which is dependent on the scalability of data consumption, lake storage capacity, and map-reduce batch processing.
- Latency which depends on message-queue efficiency, as well as databases and stream compute used in result storage.
Big Data Architecture: Serverless
Since serverless computing came on the scene, you can get going so much quicker by steering clear of DevOps. Architectural elements can now be replaced by an equivalent serverless component as part of a cloud service provider.
Examples of serverless architecture of big data pipelines are Amazon Web Services, Microsoft Azure, and Google Cloud Platform.
Production

Production requires extra vigilance. If the health of the pipeline isn’t regularly maintained, it may ultimately become unusable.
Operationalisation of a data pipeline isn’t easy. Here are some guidelines:
- Scale Data Engineering before scaling the Data Science team.
- Be industrious in clean data warehousing.
- Start simple. Start with serverle, with as few pieces as you can handle.
- Build only after careful evaluation. What are the business goals? What levers do you have to affect the business outcome?
Taking all of the above into account, we have learnt a few key takeaways from the above.
- Tuning analytics and machine learning models is only 25% effort.
- Invest in the data pipeline early because analytics and ML are only as good as data.
- Ensure easily accessible data for exploratory work.
- Start from business goals, and seek actionable insights.
Here at GPS Online we understand the value and importance of data, not just the volume or quality of the data but the means in which you process this data and conduct superior data analytics. Using the correct means to process data can not only affect the results but it can ultimately affect the spend in data processing. We are certified partners of the Google Cloud Platform, and can assist you in moving your business forward.
For more information please contact us and let our team of experts assist you.


